Relational database management systems – database management living at the edge
In the beginning, software, data, and processing power resided on a single computing asset, the mainframe, with a dumb terminal on every desk. The dumb terminal’s only function was to facilitate access to the mainframe. Then came UNIX-based systems and more dumb terminals. Then things began to change. Despite Ken Olsen of DEC’s famously misguided statement in the 1970’s “There is no reason for any Individual to have a computer in their home”, there are an estimated 1.3BN personal computers in use worldwide today (source: statista.com).
The move away from centralized computing has gained popularity and momentum over the years, especially when the cost of local storage (hard drives) eventually dropped significantly. Then came cloud computing and the computing landscape, from a data management perspective (among others), changed forever. In this article, we’ll explore relational database management systems (RDBMS), the advantages of RDBMS and databases in the cloud, IoT and edge computing.
Contrasting Non-relational DBMS and RDBMS

An RDBMS is a collection of multiple related data sets organized for searchability, organization, and reporting. The data sets are sorted into tables that contain rows (records) and columns. A closely defined relationship between tables facilitates the sharing of data. Structured query language (SQL) is used by the majority of commercial RDBMS to access the database.
Instead of tables, non-relational databases are often document-oriented. This way, non-structured data (such as articles, photos, social media data, videos) can be stored in a single document that can be easily found but isn’t necessarily categorized into fields as in a relational database. Note that storing data in bulk like this requires extra processing effort and more storage than highly organized SQL data. These types of databases are often called NoSQL and use several different models such as Key-value model, column store, document database, and graph database.
Some features and advantages of RDBMS
Storing data in tabular form with rows and columns presents several advantages when compared to a non-relational database management structure including:
- The implementation of functions to maintain accuracy, consistency, and integrity of the data
- It uses a single standardized language for different RDBMS
- It uses an advanced and non-structural querying language.
- It uses a single uniform language (DDL) for different roles.
- RDBMS can accommodate an unlimited amount of data
Here is the major advantage that set a relational database management system apart from a non-relational DBMS, the first of which we touched on above:
ACID
ACID is the Atomicity, Consistency, Isolation, Durability model relating to data storage and RDBMS is based on this model. By contrast, Non-relational DBMS doesn’t implement the ACID model, and this can cause inconsistencies in the data.
Here are some familiar examples of both Non-Relational DBMS and RDBMS
Non-Relational DBMS – MongoDB, CouchDB, Gridgain
RDBMS – SQLite, SQL Server, MySQL, RaimaDB
RDBMS and the cloud
Depending on your organization’s specific requirements, a Database as a Service (DBaaS) solution may be an attractive option, and indeed a cloud service does have some real advantages. By handing management of your database to a third party you can free up valuable personnel to focus on other tasks or empower smaller organizations to make a start without having to employ suitably qualified staff. Setting up a cloud database can be as easy as a few clicks and you’re good to go. A cloud solution also makes it straightforward to grow your database in sync with your needs as well as scaling your database up and down to accommodate peaks and troughs in demand.
However, as we move towards 5G, and a substantial increase in the speed at which data can be sent, cloud database solutions have some serious limitations – latency, bandwidth, security and availability issues being some important concerns.
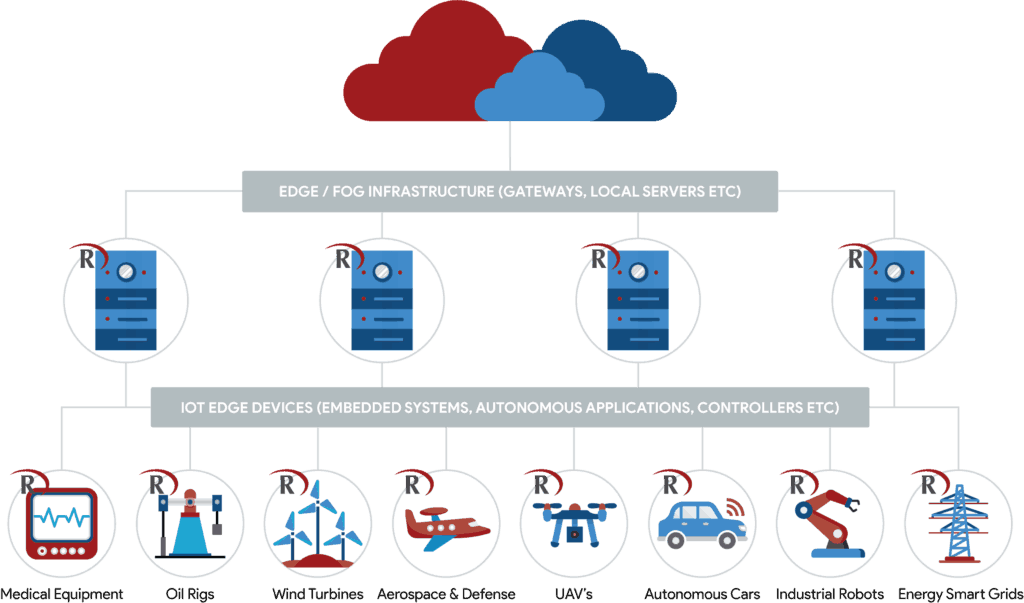
RDBMS IoT and edge
IoT devices will be equipped with many sensors and the vast amount of data they produce needs to be processed instantly to produce a meaningful and useable output. Technologies, such as cloud, won’t be able to support the real-time data processing necessary to deal with the unparalleled amount of data produced and that brings us to edge.
The rationale behind edge is to take data processing back as close as possible to the source of the data itself, thereby eliminating the round trip to the cloud and back. The result is data that is processed in real-time and made available instantly. There are certain mission-critical applications where processing data on the edge is not only desirable but critical. Interruption or latency in data flow or loss of data could have serious consequences and is therefore not acceptable.
Here are three examples of applications where instantaneous and uninterrupted data processing is critical.
Healthcare provision in rural areas – it’s estimated that approximately 30 million Americans live more than an hour from access to trauma care. Without a reliable internet connection, often an issue in rural areas, supporting such patients is impossible.
Processing data on the edge can be the difference between life and death for such patients. The applications can run with a local database when connectivity is lost and then replicate the data to a cloud database when a connection has been re-established.
Usage: Reliable, uninterrupted access to healthcare data critical to support patients in rural areas.

Autonomous vehicles (AV) – sensor data from motors, pumps, and generators on autonomous vehicles can be processed close to the source to reduce the need to send data back and forth to the cloud.
Additionally, information about road conditions, debris on the road or accidents can be used to detour other AVs and avoid delays. All useful functionality.
However, its information from sensors that prevent collisions or help an AV avoid a pedestrian that is truly critical and must be processed in near real time without delay, latency or the round trip to the cloud.
Usage: prevent accidents and possible fatalities when used in autonomous vehicles.

Structural surveillance (cameras, motion and radar sensors) – used as a preventative maintenance tool on sensitive structures such as oilfield equipment, for example. By analyzing movement, shape, and behavior of the structure, thresholds can be set for “normal” and anomalies flagged up.
As an example use case RaimaDB is embedded in Aker solutions’ Vectus™ 6.0 subsea electronics module, which improves performance and lowers risk at oil and gas installations on the seafloor.
Usage: protect structures and infrastructure by identifying abnormal states that may suggest a potential structural failure.

Data comes full circle
It’s an interesting idea that data is coming full circle, back from the cloud and closer to the source of the data itself.
The key to all of this is to have a lightweight yet powerful RDBMS, like RaimaDB that can run on low-powered edge devices. Processing data close to home on edge devices will become increasingly important to empower instant decision making through business intelligence based on the vast amounts of data generated by the IoT.
Relational database management systems are now truly living at the edge of technology.