


























How we test RaimaDB
Before the release of RaimaDB, many tests and methods are developed to ensure a robust and usable product. This is due to the stability and robustness requirements for a database being much more stringent than many other types of applications.
For instance, durability is of extreme importance. A user never wants to lose their data just because their application crashed due to a software bug or a hardware failure. Raima does everything in its power to protect the data.
Within this page will be a glimpse of some of the procedures and methods Raima follows to create a robust and well-tested product.

Database Invariant Testing
The C/C++ QA Framework, developed at Raima, has built-in support for invariant testing. An invariant test is a special type of test where a decided upon condition should be true over “some time.” This condition is called an invariant. What “some time” means will be explained further later. For a database, the invariant is typically about the data stored in the database. The invariant could be quite relaxed or it could be very strict. An example of a relaxed invariant is “the database exists.” An example of a stricter invariant is “computing some kind of a hash from all the data in the database should yield a given value.”
The QA Frameworks have special support to create, run and destroy a database invariant. A create case for a database invariant will create the database with a given schema and typically insert some data to establish a database invariant. This special case is always run before the normal run case or cases. The normal run cases are written to “maintain” the invariant. What we mean by “maintain” is specified later. After the normal cases have been run, the destroy case is executed and the invariant is no longer maintained. The time from when the create case returned and till the destroy case is called is the “some time” the invariant is maintained.
Default run
A default run of a QA Framework invariant test will do the destroy case, then the create case, followed by the normal run cases, and lastly the destroy case.
Multiple threads
The QA Framework can be instructed to run the normal run cases from multiple threads. The QA Framework will instantiate the threads and run the normal cases in parallel. A correctly written invariant test and a robust product should be able to handle this.
Processes
Another scenario is to run the test once, instruct the QA Framework to not run the destroy case at the end. This will leave the database invariant intact. Then we can run the test in multiple processes where only the normal run cases are run. A correctly written invariant test and a robust product should also be able to handle this.
Platform agnostic
Another scenario is to run the test once and instruct the QA Framework to skip the destroy case at the end, copy the database image to another architecture or operating system, and run the normal cases again. A correctly written invariant test, a robust product, and portable product should be able to handle this situation as well.
Image compatibility between versions of RaimaDB
Another scenario is to run the test once, instruct the QA Framework to skip the destroy case at the end, and save the database image for later releases. Before those later releases we restore the database images and run the tests again with only the normal cases. A correctly written invariant test, a robust product, and well-maintained product should be able to handle this situation.
Crash testing
A database invariant test can be used to ensure that database recovery is working correctly.
It is impractical to power-cycle a machine (even though we have done that in the past). Instead, we now simulate a system crash by hooking in between RaimaDB and the operating system. This can be done by preloading on Linux. We can thus simulate a system crash with lost writes. Rerunning a database invariant test with only the normal test cases should succeed for a correctly written test and a durable product.
Corrupt image testing
A database invariant test can also be used to verify that the test and RaimaDB is robust to database image corruption.
Again, using a database invariant test and performing random writes to one or more of the database files at the same time may result in a failure. Such a failure is acceptable. The requirement in this case is that RaimaDB or the test should not crash for a correctly written test and a robust product.
Remote TFS vs local TFS
A test using the C/C++ QA Framework can connect to the Transactional File Server (TFS) in many ways. As an example, the TFS may be embedded into one database invariant test running and at the same time another instance of the same database invariant test may be connected remotely to the first instance. The second instance may be running locally on the same machine as the first instance or remotely on a second machine. The second machine may have the same architecture and/or operating system as the first one, or it may be different. A lot of combinations are available here.
Verify tests
We have some tests that are not strictly a database invariant test. Among such cases are tests where the normal case or cases can be run only once. If we run the normal cases again, the QA Framework has to be instructed to only do a “verify.” A “verify” will not change the database in any way; it will just verify the database invariant. If the QA Framework is instructed to run the normal cases in parallel for a verify test from multiple threads, such an instruction will be ignored. It will always run it from one thread only.
Sequence tests
The last type of database invariant tests are sequence tests. They are just like database invariant tests except that the normal cases cannot be run in parallel. The database invariant is only valid after a successful run of all the normal cases. There is no promise that the database invariant will be valid while the normal cases are being run.
Fuzzy testing
We run a number of database invariant tests as outlined above. One of our main database invariant tests performs a lot of random operations. Every time it commits the sum of something, the sum is maintained to be 0. This test combines different types of insert, update, and delete with verification parts. The test uses nested start-update and start-read where it randomly rolls back to a previous state. For verification, it uses both start-read and star-snapshot. This test is not written for throughput but rather to stress our transaction engine and make sure that we are fully ACID.
High volume data testing
Another database invariant test is written for high throughput. Its main purpose is to do some inserts, verify that the data is there, and then delete the data it inserted. The data is inserted based on pseudo random numbers. The seed used for these inserts is also inserted. The invariant is that data corresponding to these seeds should exist. The main purpose of this test is to simply create a lot of data and stress our engine with new database files being created. Running this test in similar ways as our other tests ensures that rolling over to a new database file works even in cases that require recovery.
Replication testing
Database invariant tests, including verify tests, and sequence tests can be used to test one way replication. This will soon be added to the matrix of tests we run before a release.
Conclusion
Database invariant tests are critical for testing at Raima. Some of the complexity is handled by the QA framework and a database invariant.
Lock testing
This suite of tests has been developed specifically for our lock manager. Some tests have specifically been designed to cover general and some special cases. Others have been put in place as a result of bugs encountered in our SQL engine which may or may not have been the fault of the core engine.
With our nested locking model, we need to make sure that any updates are ACID. With respect to locking this has certain implications. For instance, with an update in combination with a read we have to make sure that the read lock is held until the update is committed, even though the application has freed the lock. A test cannot observe this through the standard API without using a second database connection. We have single threaded tests that verifies this. This makes it easier to reproduce and find bugs.
We also perform lock fuzzy testing by making randomized calls to the lock manager through the public API. This generates an enormous number of combinations that would be very hard to cover otherwise. The algorithm used in the test to verify that the locking is done correctly has been developed independently from the lock manager code in the product. This test also has the capability of writing out test code for the exact sequence of API calls used. Bugs found with this test have been added to our suite of regression tests for easier reproducibility and to protect the code from future changes.
Memcheck testing
We use Valgrind with the default tool memcheck on Linux, or Purify on Windows to find software memory issues. These tools have been proven valuable in finding many types of bugs.
However, the standard allocators used in RaimaDB do not use the C-library allocators such as malloc, calloc, realloc, and free. We instead use our own allocators where the memory is retrieved from the OS in bigger chunks or provided through the RaimaDB public API. These tools are therefore not very useful for finding memory issues when used with our standard memory allocators.
To address this, we have an alternative implementation to our standard memory allocators that uses the C-library functions mentioned above. This implementation in combination with Valgrind or Purify is used to find software memory issues. A complete run of our default set of tests for C and C++ using this approach takes several days to complete.

Memory Allocation Failure Simulation
As we discussed in the previous section, our memory allocators can be switched out. This can be done using compile time preprocessor defines or through run-time library preloading on Linux. In the following paragraph, we are describing a third implementation to our standard memory allocators.
This implementation also uses malloc and free, plus some additional header data for each allocation to help detect some incorrect uses of our standard memory allocator API. With some instrumentation from the C/C++ QA Framework, it can also simulate memory allocation failures. The QA Framework monitors the number of memory allocations and it can run this again where a given memory allocation will fail. Such runs are expected to fail with eNOMEMORY. If it does not fail as expected, necessary information will be reported so the issue can easily be reproduced.
Efence
Efence does a small subset of what memcheck can do but is much faster. It has been somewhat useful for testing RaimaDB for buffer overflow on tests that run longer.
Regression testing
When we have a bug that can be reproduced with a test, it is added as a regression test to one of our test suites. The vast majority of bugs can easily be reproduced. One class of bugs that is hard to reproduce is ones that involve multiple threads. Taking that into consideration, we have many tests that by design can be run in parallel with multiple instances of themselves or in parallel with other tests within a suite.
Code Coverage
We compile our source code using gcc with options to produce code coverage. Then we use gcov, lcov, and genhtml to produce something that can be visualized.
Helgrind testing
We use Valgrind with the tool helgrind to test RaimaDB for thread safeness. Libraries that by design are not reentrant uses mutexes to protect shared data structures. Helgrind can find places where data structures are not properly protected. However, this requires tests that use multiple threads against some shared data structures.
Our database invariant tests discussed earlier are good candidates for this type of testing as the QA Framework has the capability to run several instances of the test in parallel. Other types of tests can also be run in parallel; however, these tests will use separate databases, thus testing data structures shared between databases for thread safeness.
Writing programs for parallelism is hard. You do not want to use a mutex unless it is needed for correctness. Using mutexes affect performance. To minimize the performance impact of mutexes, we have used algorithms that do not require semaphore protection for certain shared data structures in some areas. These algorithms have been carefully designed to ensure correctness and we have used special decoration in the source code for Helgrind to suppress warnings. Such decoration is also useful as documentation and when we debug the code.
Reentrancy testing
Most of our libraries are designed to be reentrant. Other than using functionality in other libraries, anything contained within the library is completely reentrant. It means that two callers can use functionality in the library without any risk of race conditions and leakage of information from one caller to another caller as long as the program control does not go into another library that are not reentrant, they both use separate handles, and there are no buffer overflows. This type of design makes it easier to reason about correctness.
With careful design, this can easily be enforced by analyzing the compiled libraries for compliance. We have automated tests for this that analyze all our libraries, even those that are not reentrant. The test will trigger on any new additions of non-compliance. Our documentation includes information about compliance for each library.
Assert
We use asserts throughout our source code. An assert is a statement at a certain point in the code that should always be true. Using asserts properly takes careful design. For instance, asserts also have to hold in the case of an error condition.
Assertions are not designed for handling bit errors in the CPU cache or the RAM. However, for file access, one has to assume there can be bit errors. Actually, any type of disk corruption can happen in the general case and the engine must be robust enough to handle it. Any decision based on content read has to be validated or the engine has to be robust enough to not crash or run into an infinite loop. If the error happened in user data, the database engine may return incomplete or wrong data. On the other hand, if an error happened in metadata, the engine may discover that, in which case the error is reported back to the user.
It is conceptually useful to assume that there cannot be disk corruption, but any assert that is based on such an assumption has to be treated specially. In a production environment, an error has to be reported back to the user. During testing, we may want to assert depending on the type of testing we do. We use a separate type of assert for this that can be defined to behave one way or the other. This allows us to run tests where corruption is simulated and tests where corruption is assumed to not happen.
A slightly different case is handling of a database engine crash. This is a scenario that is much more likely to happen than a general disk corruption. Yet another type of assert is used for that case.
These specialized asserts allow us to run tests with different assumptions. This in combination with simulating different types of failures has proven helpful to find and fix bugs.
Portable code
One important part of software design is to make sure the code is portable. We therefore avoid certain C features that are not portable. We also make sure the file formats we use are portable. This is ensured by running our tests on a wide variety of platforms, including both actual hardware platforms and simulated platforms. We use platforms with different byte orders, different alignments, where char defaults to unsigned and signed, to mention a few.
Static Analysis
We use PC-Lint and FlexeLint for static analysis. These tools have provided valuable insight for finding some type of bugs. However, we have to be careful as certain types of rewrites of the source code can easily hide or introduce bugs. We therefore use these tools where certain warnings are globally ignored and for other warnings we decorate the source code to suppress them at specific places. See the section for Memcheck testing.
Usability testing
Part of the QA process is also to ensure that our interfaces are sane. This includes making sure the interface and the implementation is clearly separated. It also includes naming conventions, order of arguments, making sure it is complete, special cases are not harder to do than simple cases, and in general easy to use.
The APIs we have designed for RaimaDB have gone through a rigorous process to make sure we meet industry standards. The public header files also include DoxyGen documentation. We find that it is easier to keep documentation up to date if it goes together with the code.
We provide a couple of minor tests to compile small tests that include only one RaimaDB public header file. This compilation is required to succeed without any errors or warnings. This is repeated with the combination of any two header files. This is done for both our C and C++ header files.
Deadlock testing
Usually, it is a requirement that a system should not deadlock. However, RaimaDB has been designed with an API where the user can explicitly request locks. With such an API, it is possible to write an application that is guaranteed to deadlock. We therefore have tests that will intentionally deadlock when run. These tests are not run by default. They have to be run in a special environment where we can observe that they indeed deadlock and will fail if that is not the case.
Performance testing
Performance is one important aspect of any computer software but especially for a database. There are three main figures we measure. CPU load, Disk I/O, and memory usage.
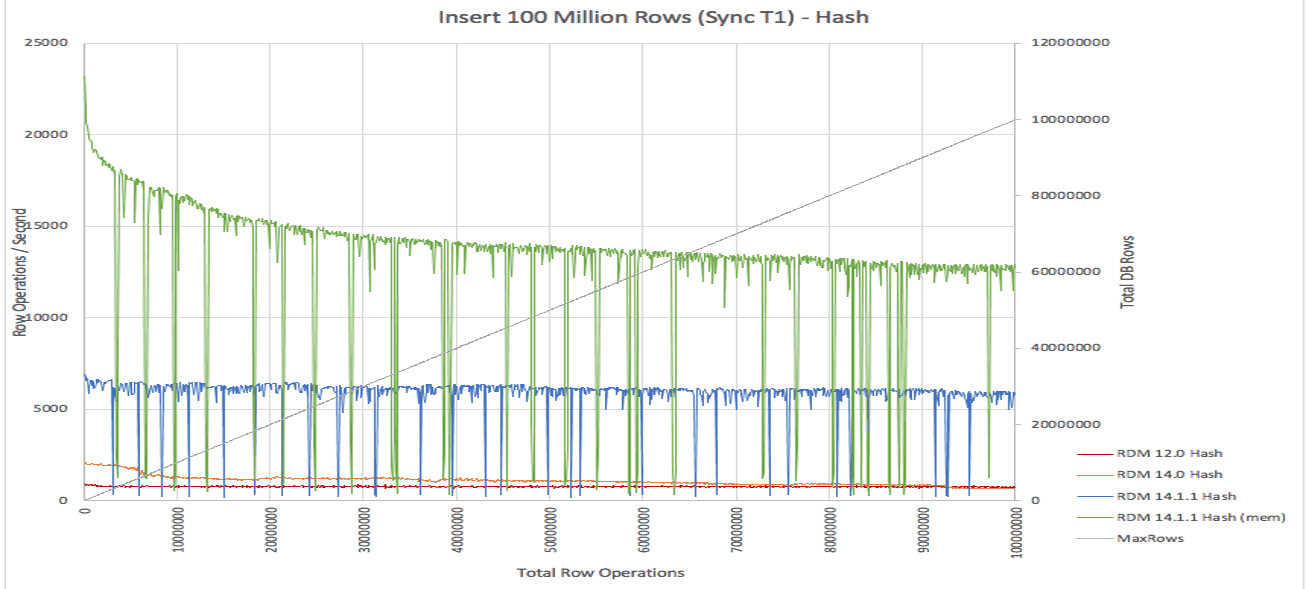
CPU Load testing
For CPU load, we have a number of performance tests. The C/C++ QA Framework has support for instantiating stopwatches that can conveniently be used to measure the performance of specific API calls. Using these in existing tests, we can obtain numbers to measure how we are doing compared to previous versions of our product.
We also have performance tests that do not use our QA framework, developed more specifically towards customer cases which may compare RaimaDB to other databases.
We are working on improvements in this area.
Disk I/O testing
With RaimaDB 14.1, we have drastically changed how data are being written to disk. Running in a mode where disk writes is minimized, RaimaDB can do insert, updates, and deletes with minimal disk I/O. The trade-offs here are increased time to open the database and increased time for crash recovery.
Testing the disk I/O is done using some of our general tests by preloading some code that will intercept certain operating system calls and collect some statistics. This is similar to the crash testing described earlier.
One advantage with this approach is that the library we use can be used for any application without having to recompile the code. There are tools on Linux that have similar approaches, but we have found that this approach is often better. It allows us to see certain write patterns we are looking for and we get a better understanding of how different use cases affect disk I/O. For instance, it is important that files are synced only when they are supposed to be synced, and that we do not have unnecessary syncs or writes.
Another aspect of disk I/O is file system cache performance. If at all possible, data that are likely to be accessed again should be clustered together, and data that are not should be grouped together as well. This way, the file system cache is less likely to cache the content that are unlikely to be accessed again. For files we know the engine will not need except for certain catastrophic failures, we use posix_fadvise to advise the kernel to drop the page or page it out from the file system cache. That this is done correctly can also be verified by intercepting this operating system call.
Memory Usage Testing
We have tests that call the public API in certain ways that should not affect the memory usage. For example, calling a certain function with the same arguments repeatedly should not increase the memory usage. These tests will fail if the memory usage is found to increase. Any test using the C/C++ QA Framework reports the memory usage in the product just before termination.
There are also tools and other mechanisms built into RaimaDB that monitor the memory usage. Those mechanisms can provide a better insight into how each sub-system behaves. Valgrind has a tool called Cachegrind that can analyze the cache performance and branch prediction of your code.
QA Frameworks
We have four different QA Frameworks developed inhouse. The one written for C/C++ is the most comprehensive one. In addition, there are ones written in Perl, Bash, and Java. They all share some similarities, which makes it easy for our team to switch between them.
Perl QA Framework
This is a later addition to our suite of QA Frameworks. Its main purpose is to test RaimaDB command line tools. It has support for feeding input into the tools and can compare the output with expected results or grep the output for certain patterns. It runs on both Unix and Windows. Many tests that were previously part of the Bash QA Framework have been rewritten to use the Perl QA Framework. That way we can run those tests both on Unix and Windows. A lot of SQL-PL is tested using this framework.
C/C++ QA Framework
Most of our C/C++ tests are written using this framework. It has the most comprehensive set of features. For details, see the section above about invariant testing.
Continuous Integration
Our build system is capable of generating make files and project files for various target platforms. It also generates shell scripts and batch files that can be used to run all or a subset of our tests in different configurations. This is used heavily in our continuous integration. It also makes it easy for developers to run the same tests manually.
Get started with RaimaDB today
Try RaimaDB for free today and see how screaming fast data management can get you to market on schedule and under budget.