


























Optimizing Data Access in a Relational Database
Relationships Between Tables
In relational databases, relationships between tables are usually established through common column values. The most common relationship is established when a column value in one table is the same value as a column in another table. In relational terminology, this is created through an “equi-join”. Relationships can also be established based on other comparisons, such as “less than.”
Equi-joins require identification of the two tables and their matching columns. A SQL query will identify the columns and a relational database engine will find all rows where the columns match. But since some columns are created with the intent of joining them with other columns, SQL DDL allows them to be identified by designating them as either “primary” keys or “foreign” keys. A primary key will uniquely identify one row in a table, while a foreign key refers to a primary key for which a relationship exists. Given this intelligence about the use of data, the relational engine will be able to structure the data representations to allow quick access to related rows.
The following snippet of SQL DDL shows an example of a primary/foreign definition between two table types:
create table author(
last_name char(13) primary key,
full_name char(35),
yr_born smallint,
yr_died smallint,
short_bio long varchar
);
create table book(
bookid char(14) primary key,
last_name char(13)
references author on delete cascade on update cascade,
title varchar(105) key[16],
descr char(61),
publisher varchar(136),
publ_year smallint range 1500 to 1980 key,
date_sold date,
price decimal(10,2)
);
The author table will always identify an author using last_name (this may require some embellishment to create uniqueness, perhaps with first name initials). The book table has its own primary key, bookid, which is available for reference by other tables. But the book table’s last_name column is the one that is being set up as the foreign reference to a row in the book table.
This primary/foreign relationship naturally fits the real-world definition of the data, as each author may have one or more books associated with their name. Another name for this type of relationship is one-to-many, where one author is related to many books.
NOTE: This example assumes that each book is written by only one author, and of course this is not always the case, since some books have multiple authors. For illustration purposes, this example demonstrates single-author books. A more advanced type of relationship, commonly called many-to-many, is implemented through an “intersection” which is described elsewhere.
Relational Engine Optimizations
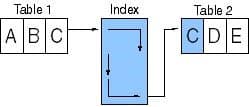
Internally, a relational database engine will normally optimize known relationships by creating indices on both primary and foreign column values. So scanning the titles of all books written by a certain author involves searching the foreign key index for all books that refer to that author, as illustrated by the following figure. Generally, Table 1 will have a unique (primary) key that is also indexed, and Table 2 will have one or more matching key values.
Index structures facilitate quick searches for key values, and when found, a “pointer” to the row containing the value is obtained.
The RaimaDB Core database engine has always had an alternative method to relate tables, in addition to indices. This method has historically been called “set” relationships, where one-to-many relationships are maintained by direct pointers from “owner” to one or more “member” rows. Rather than searching through an index, this method allows a pointer to a member row to be obtained and used directly from the contents of the owner row. See the illustration:
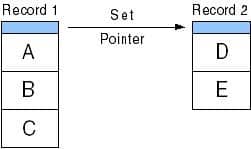
These pointers are maintained by the core engine whenever a row is created or deleted. For example, if a new book is added to the database, its author will be located immediately and the pointers will be configured such that the new book will be found in the “set” of books written by the author.
A secondary advantage and optimization of using the “set” method is that the foreign key value (e.g. last_name) does not need to be physically stored in the referencing row because it can be found in the primary row. This results in a smaller database by reducing redundant data and eliminating an index.
The “set” method allows the relational engine to move through set connections in various directions. It can move from the owner of a set instance to the first or last member of the set. From a set member, you can move to the next or previous member record, or to the owner row.
The relational equi-join, which is by far the most common method to associate tables in a relational database, has been optimized in RaimaDB by using the “set” method. This is faster than using indices alone because direct pointers between rows are constantly maintained, making navigation from row to row go very quickly, and because referring rows do not contain redundant data values